Haar Cascades Process
1. Haar Feature Selection2. Creating Integral Images
3. Adaboost Training
4. Cascading Classifiers
1. Haar Feature Selection
이미지에서 하르 특징(Haar Feature)를 계산한다.
모든 가능한 크기의 커널을 가지고 이미지 전체를 스캔하여 하르 특징을 계산
ex) 24x24 크기의 위도우를 사용시 160000개 이상의 하르 특징을 구한다.
하르 특징은 이미지를 스캔하면서 위치를 이동시키는 인접한 직사각형들의 영역내에 있는 픽셀의 합의 차이를 이용한다.
사각 영역 내부의 픽셀들을 빠르게 더하기 위해 적분 이미지(integral image) 사용
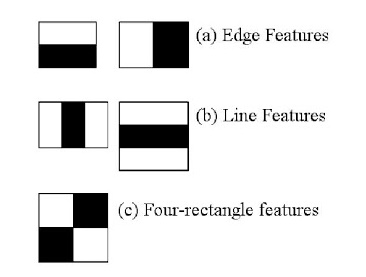
두 개의 사각형으로 구성된 하르 특징 값은 두 사각 영역 내부에 있는 픽셀들을 합하여 검은색 영역의 합에서 흰색 영역의 합을 빼서 구한다.
(a, b 3개의 사각형 중에서 검은색 사각 영역 내부에 있는 픽셀 합에서 바깥에 있는 두 개의 흰색 사각 영역 내부의 픽셀 합을 뺀다.
c는 대각선에 위치한 영역간의 차이를 구한다.)
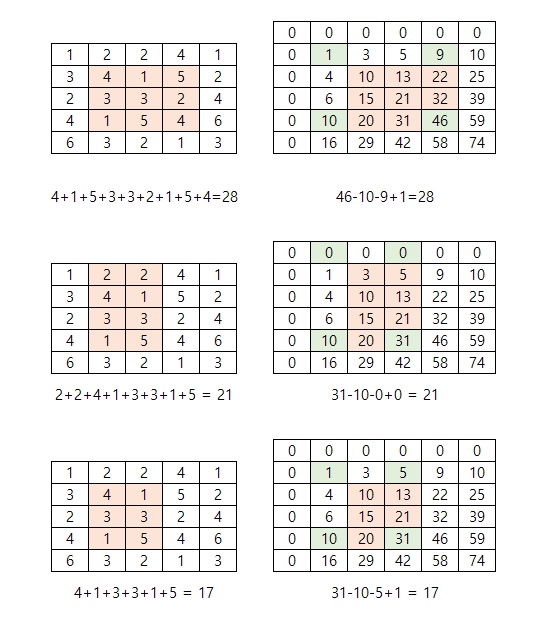
2. Integral Images(적분 이미지)
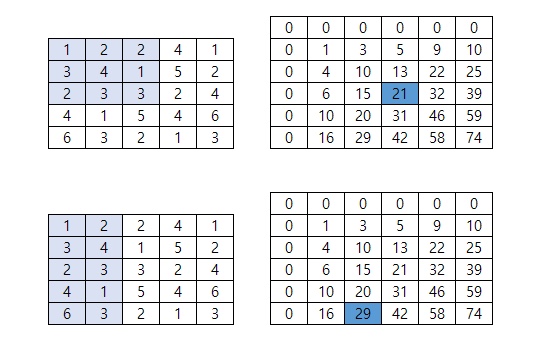
기존 이미지에서 너비와 높이를 1씩 더해서 더 큰 이미지를 만든 후에 가장 왼쪽, 위쪽은 0으로 채운다.
기존 이미지 영역을 지정하여 내부 값들의 합을 구한 후,
적분 이미지에서 원본에 지정한 영역의 오른쪽 아래 픽셀에 대응하는 위치에 합을 입력
3. Adaboost Training
이미지에서 앞에 선택한 하르 특징을 사용하여 특징을 계산한다.
160000개 이상의 많은 특징이 검출된ㄴ데 엄굴 검출을 하는데 도움이 되는 의미있는 특징을 골라내기위해서
Adaboost를 사용한다.
Adaboost는 최적의 특징을 선택하기 위해서 모든 학습 이미지에 특징을 적용한다.
각 특징에 대해 얼굴이 포함된 이미지와 얼굴이 없는 이미지를 분류하기 위한 최적의 임계값(threshold)를 찾는다
(흰색 영역과 검은색 영역의 차이가 일정 임계값 이상이면 얼굴을 위한 특징으로 인식)
0. 처음에는 모든 하르 특징이 동일한 가중치를 가진다.
1. 모든 하르 특징에 대해 학습 데이터 세트를 사용하여 분류한 결과 각 하르 특징의 에러률을 계산하고,
잘못 분류하는 하르 특징에는 가중치를 증가시킨다.->성능이 좋은 하르 특징은 낮은 에러률을 가진다.(선택)
2. 요구하는 정확성 또는 요구하는 에러율 획득 또는 요구하는 개수의 특징을 발견할 때까지 반복
최종 분류자는 약 분류자들에 대한 가중치 합이다.
약 분류자를 묶으면 이미지를 분류할 수 있게 된다.(boosting ensemble)
4. Cascade Classifier
위와 같이 계산하면, 계산량이 많기 때문에 비효율적이다.
이미지의 대부분의 공간이 얼굴이 없는 영역이다.
현재 윈도우가 있는 영역이 얼굴 영역인지 단계별로 체크하는 방법을 사용
낮은 단계에서 짧은 시간에 얼굴 영역인지 판단
상위 단계로 갈수록 좀더 시간이 오래걸리는 연산을 수행
(여러개의 단계를 그룹으로 묶어서 사용한다.)
첫 번째 단계에서 얼굴 영역이 아니라고 판정이 나면 다음 위치로 위도루를 이동하여 다음 단계의 특징을 적용
Haar-cascade Detection in OpneCV
opnencv/data/haarcascades